Aumento do Faturamento da Empresa com Previsão de Churn¶
Antes de mais nada, vou explicar de forma breve o que é Churn, e todos seus conceitos envolvidos. Vamos lá!¶
O que é churn?¶
Churn é a medida de quantos clientes param de usar um produto. Isso pode ser medido com base no uso real ou falha na renovação (quando o produto é vendido usando um modelo de assinatura). Frequentemente avaliada por um período de tempo específico, pode haver uma taxa de churn mensal, trimestral ou anual.
Quando novos clientes começam a comprar e/ou usar um produto, cada novo usuário contribui para a taxa de crescimento do produto. Inevitavelmente, alguns desses clientes acabarão por descontinuar a sua utilização ou cancelar a sua subscrição; ou porque mudaram para um concorrente ou solução alternativa, não precisam mais das funções do produto, estão insatisfeitos com a experiência do usuário ou não podem mais arcar ou justificar o custo. Os clientes que param de usar/pagar são o “churn” por um determinado período de tempo.
Como é calculado o Churn?¶
Em sua forma mais simplista, a taxa de cancelamento é a porcentagem do total de clientes que param de usar/pagar durante um período de tempo. Assim, se houvesse 10.000 clientes totais em março e 1.000 deles deixassem de ser clientes, a taxa de churn mensal seria de 10%.

Por que o Churn ocorre?¶
Muitos fatores influenciam as razões de um cliente para o Churn. Pode ser o fato de haver um novo concorrente no mercado oferecendo preços melhores ou talvez o serviço que eles estão recebendo não esteja à altura, e assim por diante. Portanto, não há uma resposta correta sobre por que exatamente o cliente deseja churn, porque, como você pode ver, há muitos fatores que influenciam.
Prós e Contras da Taxa de Churn¶
| Prós | Contras |
|---|---|
| Fornece clareza sobre a qualidade do negócio | Não fornece clareza sobre os tipos de clientes que saem: novos versus antigos |
| Indica se os clientes estão satisfeitos ou insatisfeitos com o produto ou serviço | Não diferencia os tipos de empresas na comparação do setor: startups, em crescimento e consolidadas |
| Permite a comparação com concorrentes para medir um nível aceitável de churn | |
| Fácil de calcular |
O trabalho de um cientista de dados é encontrar esses padrões nos dados fornecidos e ver quais fatos são produzidos durante a análise de dados.¶
Diante disso, vamos para o problema de negócio e contextuar a situação ao Churn Rate.¶
Empresa TopBank¶
a descrição a seguir é totalmente fictícia, apenas contextualização para um problema de negócio.¶
A TopBank é uma grande empresa de serviços bancários. Ela atua principalmente nos países da Europa oferecendo produtos financeiros, desde contas bancárias até investimentos, passando por alguns tipos de seguros e produto de investimento.
O modelo de negócio da empresa é do tipo serviço, ou seja, ela comercializa serviços bancários para seus clientes através de agências físicas e um portal online.
O principal produto da empresa é uma conta bancária, na qual o cliente pode depositar seu salário, fazer saques, depósitos e transferência para outras contas. Essa conta bancária não tem custo para o cliente e tem uma vigência de 12 meses, ou seja, o cliente precisa renovar o contrato dessa conta para continuar utilizando pelos próximos 12 meses.
Segundo o time de Analytics da TopBank, cada cliente que possui essa conta bancária retorna um valor monetário de 15% do valor do seu salário estimado, se esse for menor que a média e 20% se esse salário for maior que a média, durante o período vigente de sua conta. Esse valor é calculado anualmente.
Por exemplo, se o salário mensal de um cliente é de 1.000,00 e a média de todos os salários do banco é de 800,00. A empresa, portanto, fatura 200,00 anualmente com esse cliente. Se esse cliente está no banco há 10 anos, a empresa já faturou 2.000,00 com suas transações e utilização da conta. (Valores em reais).
Nos últimos meses, o time de Analytics percebeu que a taxa de clientes cancelando suas contas e deixando o banco, atingiu números inéditos na empresa. Preocupados com o aumento dessa taxa, o time planejou um plano de ação para diminuir taxa de evasão de clientes.
Preocupados com a queda dessa métrica, o time de Analytics da TopBottom, contratou você como consultor de Data Science para criar um plano de ação, com o objetivo de reduzir a evasão de clientes, ou seja, impedir que o cliente cancele seu contrato e não o renove por mais 12 meses. Essa evasão, nas métricas de negócio, é conhecida como Churn.
De maneira geral, Churn é uma métrica que indica o número de clientes que cancelaram o contrato ou pararam de comprar seu produto em um determinado período de tempo. Por exemplo, clientes que cancelaram o contrato de serviço ou após o vencimento do mesmo, não renovaram, são clientes considerados em churn.
Outro exemplo seria os clientes que não fazem uma compra à mais de 60 dias. Esse clientes podem ser considerados clientes em churn até que uma compra seja realizada. O período de 60 dias é totalmente arbitrário e varia entre empresas.
O Desafio¶
Como um Consultor de Ciência de Dados, criarei um plano de ação para diminuir o número de clientes em churn e mostrar o retorno financeiro da sua solução.
Ao final da consultoria, entregarei ao CEO da TopBottom um modelo em produção, que receberá uma base de clientes via API e retornará essa mesma base “scorada”, ou seja, um coluna à mais com a probabilidade de cada cliente entrar em churn.
Além disso, você precisará fornecer um relatório reportando a performance do seu modelo e o impacto financeiro da sua solução. Questões que o CEO e o time de Analytics gostariam de ver em seu relatório:
- Qual a taxa atual de Churn da TopBank? Como ela varia mensalmente?
- Qual a Performance do modelo em classificar os clientes como churns?
- Qual o retorno esperado, em termos de faturamento, se a empresa utilizar seu modelo para evitar o churn dos clientes?
- Uma possível ação para evitar que o cliente entre em churn é oferecer um cupom de desconto, ou alguma outro incentivo financeiro para ele renovar seu contrato por mais 12 meses.
Dicionário de dados¶
Cada linha representa um cliente e cada coluna contém alguns atributos que descrevem esse cliente. O conjunto de dados inclui informações sobre:
- RowNumber: O número da coluna
- CustomerID: Identificador único do cliente
- Surname: Sobrenome do cliente.
- CreditScore: A pontuação de Crédito do cliente para o mercado de consumo.
- Geography: O país onde o cliente reside.
- Gender: O gênero do cliente.
- Age: A idade do cliente.
- Tenure: Número de anos que o cliente permaneceu ativo.
- Balance: Valor monetário que o cliente tem em sua conta bancária.
- NumOfProducts: O número de produtos comprado pelo cliente no banco.
- HasCrCard: Indica se o cliente possui ou não cartão de crédito.
- IsActiveMember: Indica se o cliente fez pelo menos uma movimentação na conta bancário dentro de 12 meses.
- EstimateSalary: Estimativa do salário mensal do cliente.
- Exited: Indica se o cliente está ou não em Churn.
# Instala pacotes
!pip install -q pycaret --user
!pip install -q sweetviz --user
!pip install -q autoviz --user
!pip install -q gradio --user
# Carregando as bibliotecas
import time
import sklearn
import datetime
import pandas as pd
import numpy as np
import matplotlib as m
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from pycaret.classification import *
warnings.filterwarnings("ignore")
# Carrega o dataset
df1 = pd.read_csv("churn.csv", encoding = 'utf-8')
# Verifica o shape
df1.shape
# Visualiza os dados
df1.head()
Análise exploratória¶
Vamos explorar os dados para compreender as relações e influências ou não entre as variáveis dependentes e alvo.
# Verifica valores unicos
df1.nunique()
df1.isnull().sum()
# Tipos de dados
df1.dtypes
# Resumo das colunas numéricas
df1.describe()
# Deletando colunas irrelevantes para análise
df1 = df1.drop(columns = ['RowNumber', 'CustomerId', 'Surname'])
df1.head()
# Proporção entre clientes em churn ou não
(df1['Exited'].value_counts()/len(df1['Exited']))*100
Vimos que a taxa de churn está em torno dos 20,3%. Traduzindo para números reais se em um mês entram 10 mil clientes, 2 mil deles irão sair até o fim do mês. Vamos fazer algumas análises para poder entender o que está acontencendo com nossos clientes e possíveis motivos que ocasionam o Churn, além de criar um modelo que consiga atrair mais clientes e diminuir essa taxa.
Análise Descritiva¶
Overview das variáveis numéricas¶
# Plot
# Tamanho da figura
plt.figure(1, figsize = (20, 12))
# Inicializa contador
n = 0
# Loop pelas colunas
for x in ['CreditScore', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard', "EstimatedSalary"]:
n += 1
plt.subplot(3, 4, n)
plt.subplots_adjust(hspace = 0.5, wspace = 0.5)
sns.histplot(df1[x], bins = 15)
plt.title("Histplot de {}".format(x))
plt.show()

Vamos criar um gráfico de estimativa de densidade do Kernel (KDE) pelo valor do alvo. KDE é uma maneira de identificar se existe uma correlação entra a variável dependente e alvo, nesse caso a correlação entre idade e churn.¶
# KDE plot
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.kdeplot(df1.loc[df1['Exited'] == 1, 'Age'], label = 'Clientes em Churn')
sns.kdeplot(df1.loc[df1['Exited'] == 0, 'Age'], label = 'Clientes fora do Churn')
plt.legend()
plt.xlim(left = 18, right = 90)
plt.xlabel('Idade')
plt.ylabel('Densidade')
plt.title('Distribuição de idade em porcentagem com a variável Churn');

# Plot do Valor monetário em conta dos clientes dentro e fora do churn
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.histplot(data = df1, x = 'Balance', hue = 'Exited', kde = True, multiple = 'dodge')
plt.legend(['Em churn', 'Fora do churn'])
plt.xlabel('Valor monetário em conta')
plt.ylabel('Contagem')
plt.title('Valor monetário em conta X Distribuição total');

# Plot do estimativa salarial mensal dos clientes dentro e fora do churn
plt.figure(figsize = (15,8))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.histplot(data = df1, x = 'EstimatedSalary', hue = 'Exited', kde = True, multiple = 'dodge')
plt.legend(['Em churn', 'Fora do churn'], loc = 'upper right')
plt.xlabel('Estimativo Salarial Mensal')
plt.ylabel('Contagem')
plt.title('Estimativa Salarial Mensal dos clientes em churn e fora do churn');

# Plot do Score de Crédito dos clientes dentro e fora do churn
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.histplot(data = df1, x = 'CreditScore', hue = 'Exited', kde = True, multiple = 'dodge')
plt.legend(['Em churn', 'Fora do churn'])
plt.xlabel('Pontuação de Crédito')
plt.ylabel('Contagem')
plt.title('Pontuação de Crédito dos clientes');

# Contagem de clientes por região
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.countplot(x = 'Geography', hue = 'Exited', data = df1)
plt.legend(labels = ['Fora do Churn', 'Em Churn'])
plt.xlabel("Região")
plt.ylabel("Contagem")
plt.title("Distribuição de clientes por região")

# Contagem de clientes por produtos
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.countplot(x = 'NumOfProducts', hue = 'Exited', data = df1)
plt.legend(labels = ['Fora do Churn', 'Em Churn'], loc = 'upper right')
plt.xlabel("Número de Produtos")
plt.ylabel("Contagem")
plt.title("Distribuição de clientes por produto")

from matplotlib.cm import get_cmap
from matplotlib.patches import Patch
# Criando um dataframe secundário para analisar as variáveis categoricas Geography, NumOfProducts e Exited
df2 = df1[['Geography', 'NumOfProducts', 'Exited']]
df2['Dummy'] = np.ones(len(df2))
# Agrupando pelas categorias desejadas
grouped = df2.groupby(by=['Geography','Exited','NumOfProducts' ]).count().unstack()
# Lista dos clientes em churn ou fora, para usar como categoria depois
kinds = grouped.columns.levels[1]
# Cores para o grafico
colors = [get_cmap('viridis')(v) for v in np.linspace(0,1,len(kinds))]
sns.set(context="talk")
nxplots = len(grouped.index.levels[0])
nyplots = len(grouped.index.levels[1])
fig, axes = plt.subplots(nxplots,
nyplots,
sharey=True,
sharex=True,
figsize=(15,10))
fig.suptitle('Agrupamento de Clientes por Região e \nQuantidade de Produtos')
# plot
for a, b in enumerate(grouped.index.levels[0]):
for i, j in enumerate(grouped.index.levels[1]):
axes[a,i].bar(kinds,grouped.loc[b,j],color=colors)
axes[a,i].xaxis.set_ticks([])
axeslabels = fig.add_subplot(111, frameon=False)
plt.tick_params(labelcolor='none', top=False, bottom=False, left=False, right=False)
plt.grid(False)
axeslabels.set_ylabel('Localidade',rotation='horizontal',y=1,weight="bold")
axeslabels.set_xlabel('Em churn ou não',weight="bold")
# Rotulos dos eixo X e Y
for i, j in enumerate(grouped.index.levels[1]):
axes[nyplots,i].set_xlabel(j)
for i, j in enumerate(grouped.index.levels[0]):
axes[i,0].set_ylabel(j)
# Ajuste manual para abrir espaço para a legenda
fig.subplots_adjust(right=0.78)
fig.legend([Patch(facecolor = i) for i in colors],
kinds,
title="Quantidade de Produtos",
loc="upper right")

# Contagem por clientes que tem ou não cartao de credito
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.countplot(x = 'HasCrCard', hue = 'Exited', data = df1)
plt.legend(labels = ['Fora do Churn' , 'Em Churn'])
plt.xlabel("Clientes que possuem ou não cartao de credito")
plt.ylabel("Contagem")
plt.title("Distribuição de clientes que possuem ou não cartão de crédito")

# Distribuição de clientes por tempo de empresa fora do churn
plt.figure(figsize = (15,8))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.countplot(x = 'Tenure', hue = 'Exited', data = df1)
plt.legend(labels = ['Fora do Churn' , 'Em Churn'])
plt.xlabel("Anos na empresa")
plt.ylabel("Contagem")
plt.title("Distribuição de clientes em churn ou não por anos de permanência na empresa")

# Distribuição de clientes que fazem movimentação na conta num período de 12 meses em ou fora do churn
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.countplot(x = 'IsActiveMember', hue = 'Exited',data = df1)
plt.legend(['Fora do Churn' , 'Em Churn'])
plt.xlabel("Membro Ativo")
plt.ylabel("Contagem")
plt.title("Distribuição de membros ativos em ou fora do churn")

# Distribuição de clientes por genero em ou fora do churn
plt.figure(figsize = (15,6))
plt.style.use('seaborn-colorblind')
plt.grid(True, alpha = 0.5)
sns.countplot(x = 'Gender', hue = 'Exited',data = df1)
plt.legend(labels = ['Fora do Churn' , 'Em Churn'])
plt.xlabel("Gênero")
plt.ylabel("Contagem")
plt.title("Distribuição por gênero em ou fora do churn")

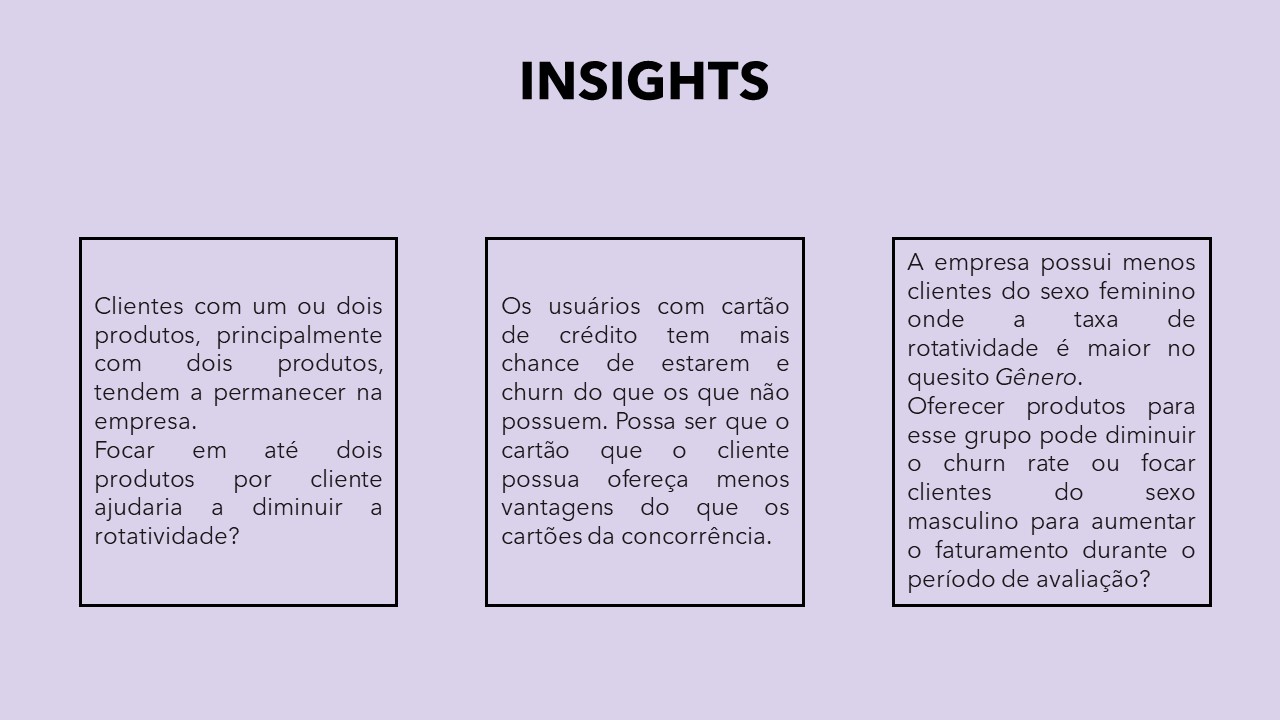
Após a Análise Exploratória dos dados, vamos verificar abaixo alguns insights para o problema proposto.
Insights do problema de negócio ¶


# Gerando plot de correlação entre as variáveis
# Armazenando correlação do dataframe
corr = df1.corr()
# Gerando corrplot
plt.figure(figsize = (15,10))
sns.heatmap(corr, annot = True, fmt = '.3f')
plt.title("Correlação entre as variáveis")
plt.show()

# Proporção entre clientes em churn ou não
(df1['Exited'].value_counts()/len(df1['Exited']))*100
Através do código acima vimos que há um desbalanceamento dos dados na variável alvo (Exited, o que pode enviesar o modelo e atrapalhar nas decisões futuras). Vamos Utilizar o PyCaret, uma ferramenta completa que consegue treinar o dataset com vários modelos, mostrar as diferentes métricas de desempenho para cada um deles, tunar o modelo escolhido e mostrar todo esse resultado.
# Configurando o modelo para o dataset
s = setup(df1, target = "Exited", fix_imbalance = True)
Vamos rankear e selecionar o melhor modelo de acordo com a métrica AUC.
# Comparando todos os modelos
best_model = compare_models(sort = 'AUC')
# Print dos parametros do melhor modelo
print(best_model)
# Confusion matrix do modelo sem melhorias
plot_model(best_model, plot = 'confusion_matrix')

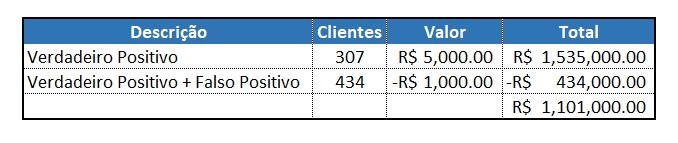
A Confusion Matrix acompanha o conjunto de teste, um split de 70/30: 70% do dataset utilizado para treino e 30% para teste.
- Das 3000 linhas separadas para treino, ou seja, dos 3000 clientes Temos 307 Verdadeiros Positivo (10%) - Os quais podemos oferecer alguma promoção;
- 4,2% dos clientes, 127 para ser exato, seria onde perderíamos dinheiro por se tratarem de Falsos Positivo, identificados como clientes em Churn porém não são verdadeiramente, ocasionando um custo extra;
- 325 clientes (11%), seriam Falsos Negativo, clientes que entrariam em Churn porém não seriam identificados como tal, ocasionando na perda real deles sem nenhuma tentativa de incentivo para permanência destes.
# plot AUC do melhor modelo original
plot_model(best_model, plot = 'auc')

# Plot das variáveis mais relevantes
plot_model(best_model, plot = 'feature')

Nós vamos utilizar de uma função do PyCaret para automaticamente tunar os hiperparâmetros do modelo, afim de trazer um melhor resultado diante as métricas observadas.
# Tunando o melhor modelo
tuned_best_model = tune_model(best_model)
O modelo teve uma melhoria de apenas 0,01%, porém muda na quantidade de Verdadeiros Positivos de forma razoável, influenciando no resultado final.¶
# Plot AUC do melhor modelo tunado
plot_model(tuned_best_model, plot = 'auc')

# Confusion matrix do modelo sem melhorias
plot_model(tuned_best_model, plot = 'confusion_matrix')

Com a melhoria do modelo temos as seguintes informações:
- Dos 3000 clientes temos agora 311 Verdadeiros Positivo - Para os quais podemos oferecer alguma promoção;
- Manteve a quantidade de Falsos positivos, onde seria o público para quem perderíamos dinheiro, identificados como clientes em Churn porém não são verdadeiramente;
- E uma diminuição para 321 clientes Falsos Negativo, clientes que entrariam em Churn porém não seriam identificados como tal.
Num problema de negócio como esse de rotatividade de cliente, o retorno financeiro dos verdadeiros positivos é diferente do custo dos falsos positivos. Vamos concretizar essa teoria com as seguintes posições:
Oferecer um voucher de R$1000,00 a todos os clientes identificados como churn (Verdadeiro Positivo + Falso Positivo);
Se interrompermos o churn, ganhamos R$5000,00 em valor de permanência do cliente na empresa.
Com a suposições acima e os valores da Confusion Matrix, vamos calcular o impacto financeiro desse modelo:¶
Com o PyCaret conseguimos adicionar uma nova métrica que vai de acordo com o problema proposto. Para isso vamos criar uma métrica de lucro, que é o que queremos aumentar no final de avaliação de churn.¶
# Cria uma função personalizada
def calcula_profit(y, y_pred):
tp = np.where((y_pred == 1) & (y == 1), (5000-1000), 0)
fp = np.where((y_pred == 1) & (y == 0), -1000, 0)
return np.sum([tp,fp])
# Adiciona metrica ao PyCaret
add_metric('profit', 'Profit', calcula_profit)
# Agora vamos comparar os modelos com a nova métrica
best_model_profit = compare_models(sort = 'Profit')
Podemos verificar que na coluna Profit o modelo com melhor desempenho em questões financeiras é o LDA (Análise Discriminante Linear), que está longe de ser o melhor modelo através da métrica AUC, com valor de 83.08%. Agora vamos conferir a Confusion Matrix do modelo.
# Confusion Matrix LDA
plot_model(best_model_profit, plot = 'confusion_matrix')

Acontece que agora o modelo aumentou tanto os valores de Verdadeiros Positivos e Falsos Positivos, e isso é relevante para nosso caso porque estamos focados em entregar produtos para quem o modelo irá prever que estará em Churn, tanto os Verdadeiros Positivos como Falsos Positivos. Agora vamos aplicar as mesmas suposições que comentei logo antes:
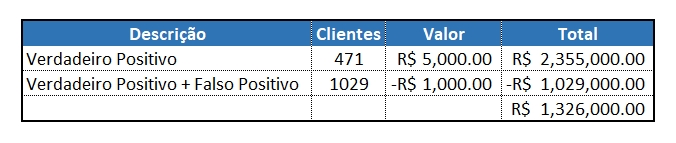
- No modelo tunado que utilizamos para verificação de lucro que a empresa teria resgatando clientes em Churn, teríamos um lucro total de R$ 1.101.000,00;
- No modelo selecionado a partir da métrica criada conseguimos um retorno financeiro de R$ 1.326.000,00;
- Isso significa 17% de aumento ou R$ 225.000,00 em valores monetários, apenas na escolha de uma métrica que melhor se posiciona para o caso
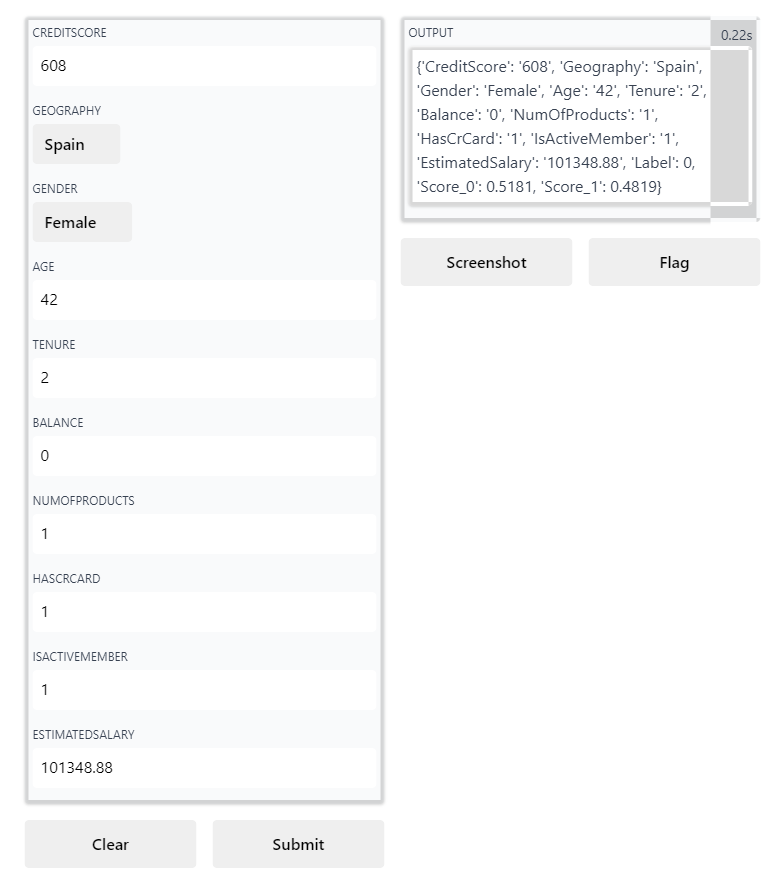
Na versão 2.3.6 do PyCaret houve também muita coisa nova, como o deploy do modelo de forma bastante prática.¶
É possível criar um app apenas com uma linha de código. Com base na biblioteca Gradio, cria-se um web app em que você pode inserir os valores das variáveis independentes e o app informa o resultado previsto. Vamos conferir abaixo.¶
# Cria o app
create_app(best_model_profit)
Chegamos ao fim de um Projeto de Churn de clientes, com insights, avaliações de modelos preditivos, métricas, resultado financeiro e aplicação web de todo esse estudo de caso.¶
Contato:
- matheus131998@gmail.com
- https://www.linkedin.com/in/matheus-oliveira-064242129/